

building an ai system for electronics data extraction
how we built parallel extraction pipelines, race-loop streaming, and schema validation to turn 200-page datasheets into production-ready footprints.
this is part 1 in a series on how we at niyam ai are building ai tooling in the electronics manufacturing world, piloting our tools with fortune-10 companies. this piece is an intro on setting up the ai system. next article will be about evals.
every electronic product starts with a pcb design. every pcb design depends on accurate footprints - the physical and electrical definition of how a component attaches to the board.
that data lives in datasheets: 50-200 page pdfs written by thousands of vendors, all with different conventions.
engineers manually extract:
- pin assignments (power, ground, signal)
- physical dimensions (package size, pitch, lead width)
- electrical limits (voltage, current, thermal)
the failure mode is brutal: one wrong value → board respin → weeks lost.
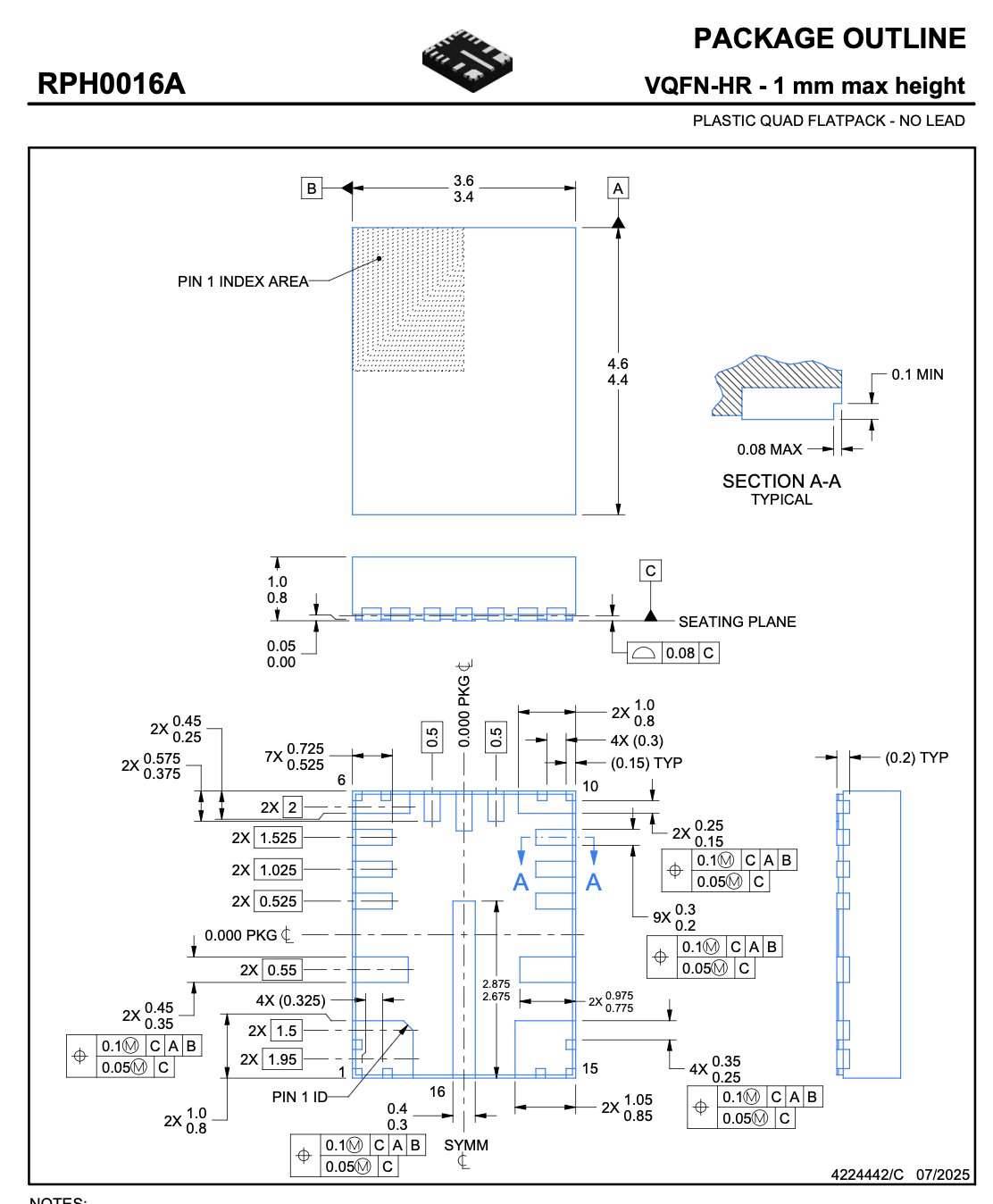
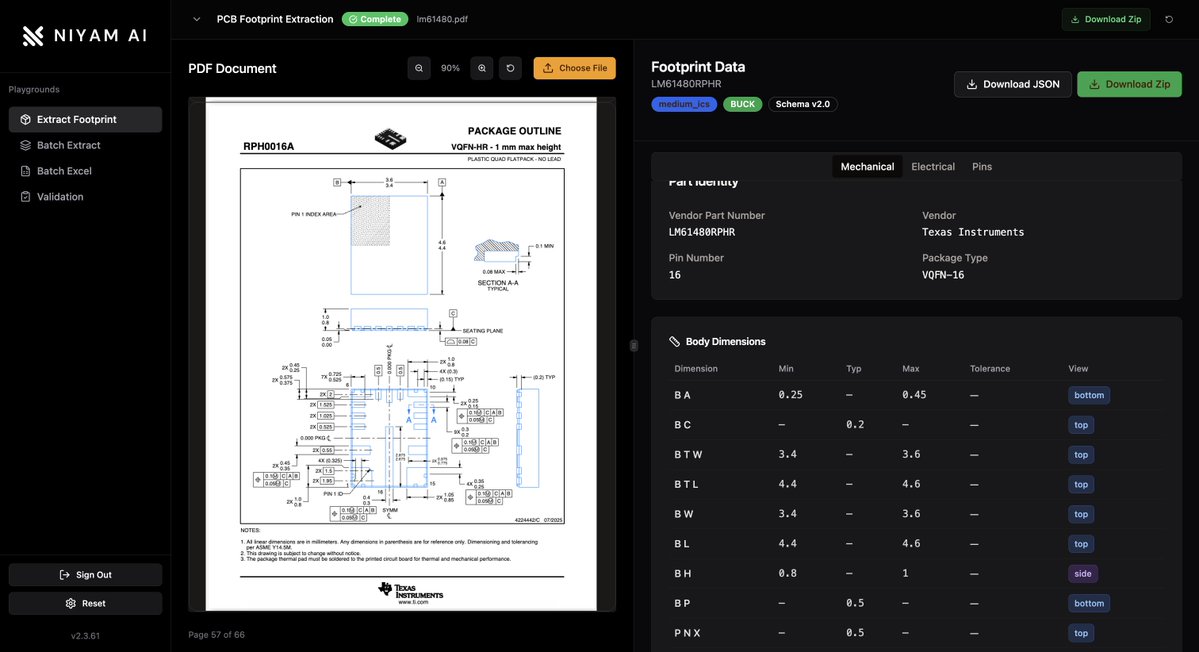
the problem is inconsistency, not length.#
the same concept appears under different names, in different table layouts, on different pages, sometimes only implied in diagrams. parsing tables isn't enough - the system has to understand meaning.
therefore, an extraction system can't rely on document structure. it has to work on semantics. "pin configuration", "terminal assignment", and "lead description" mean the same thing. recognizing that equivalence is the actual work.
one thing we noticed early: datasheets contain mostly orthogonal information i.e. pin tables don't depend on dimension drawings. electrical specs don't depend on package geometry. forcing these into a serial pipeline wastes time. so we run specialized extractors in parallel, each owning a single domain:
- pins
- dimensions
- electrical specs
- package classification
- visual analysis
this leads to three benefits:
- total runtime = slowest extractor, not the sum
- users see partial results as domains complete
- one domain failing doesn't block the others
the race-loop pattern#
most async code uses promise.all() - wait for everything, return once.
we use a race-loop instead: yield results as each extractor finishes, merge incrementally.
for a 2-3 minute extraction, this changes how it feels. engineers can start validating pin data while dimensional analysis is still running.
llms don't reliably produce valid formats.#
they return strings instead of numbers. malformed nesting. missing fields. extra fields. this breaks coordinate math.
solution: schema-first ownership.
llms generate candidate structures. schemas validate, coerce, normalize, or reject. malformed data never reaches downstream logic.
this matters because downstream systems assume numerical precision. footprint generation can't tolerate "2.5" when it expects 2.5.
dealing with different packages#
packages like a 144-pin qfp, a 16-pin soic, and a bga all need different pin-placement logic. same interface, different geometry.
we use a strategy pattern - each package type owns its geometry, pin ordering, and coordinate math behind a common contract.
the pipeline streams everything.#
server-sent events backed by async generators. information flows continuously instead of arriving in one lump at the end.
events fall into three buckets:
- progress events (user feedback)
- data events (chunked to avoid size limits)
- lifecycle events (persisted for resumability)
failures happen.#
visual extraction might fail while pin tables succeed. one page might not parse while others do. confidence scores surface uncertainty instead of hiding it.
we'd rather give engineers usable partial data than a clean failure message.
what we learned while building niyam:#
- parallel extractors cut wall-clock time
- race-loop streaming makes long jobs feel responsive
- schemas contain llm chaos
- strategy patterns isolate geometry complexity
- partial success beats clean failure
the hard part isn't "using ai."
the hard part is encoding decades of domain knowledge: inconsistent vendor language, fragmented representations, sub-millimeter accuracy requirements.
the architecture handles complexity. the expertise is knowing what has to be right.
that's what we're building at niyam ai - we turn datasheets into production-ready footprints - hours of manual work compressed into minutes. if you're dealing with component data at scale, drop me a line.